| CPC H04R 3/002 (2013.01) [H04R 1/1016 (2013.01); H04R 25/02 (2013.01)] | 17 Claims |
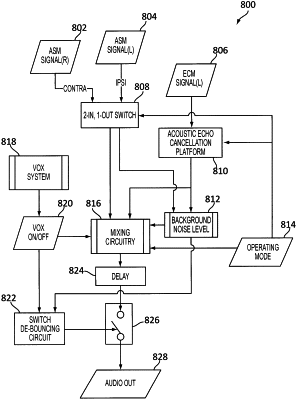
|
1. An earphone comprising:
an ambient microphone configured to measure an acoustic environment and generate an ambient signal;
an ear canal microphone configured to generate an internal signal;
a speaker;
a memory that stores an ambient gain and an audio content gain; and
a processor, wherein the processor is operatively connected to the microphone, wherein the processor is operatively connected to the speaker, wherein the processor is operatively connected to the memory, wherein the processor receives an audio content, wherein the audio content is at least one of music, a voice signal or a combination thereof;
wherein the processor receives the ambient signal;
wherein the processor receives the internal signal;
wherein the processor detects when a user is speaking by analyzing the difference between the internal signal and the ambient signal;
wherein the processor adjusts the ambient gain if it is detected that the user is speaking;
wherein the processor adjusts the audio content gain if it is detected that the user is speaking;
wherein the processor modifies the ambient signal to generate a modified ambient signal by applying the ambient gain to the ambient signal;
wherein the processor modifies the audio content by applying the audio content gain to the audio content to generate a modified audio content;
wherein the processor mixes the modified ambient signal and the modified audio content to generate a mixed signal; and
wherein the processor sends-the mixed signal to the speaker.
|