| CPC H04L 51/02 (2013.01) [G06F 40/30 (2020.01); G06N 20/00 (2019.01)] | 20 Claims |
|
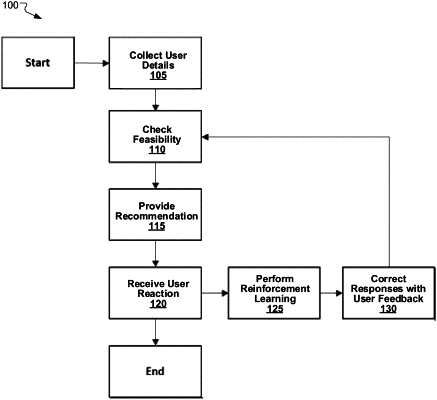
1. A method for generating and correcting chatbot responses based on reinforcement learning (RL), the method comprising:
receiving user data associated with a user in a chatbot conversation;
providing a first recommendation to the user based on the user data and one or more RL models;
detecting user feedback to the first recommendation in the chatbot conversation;
determining whether to assign a positive reward or a negative reward to the user feedback based on sentiment analysis performed on the user feedback;
calculating a negative or positive reward score for the first recommendation based on the positive or negative reward assigned to the user feedback;
retraining the one or more RL models using the reward score, the user data, the first recommendation, and the user feedback, the user data including user preference changes over time; and
modifying the first recommendation to generate a second recommendation using the one or more retrained RL models when the negative reward is assigned to the user feedback of the first recommendation, wherein the first recommendation continues to be used in retraining the one or more RL models until a condition of the one or more RL models is met.
|