| CPC G10L 25/18 (2013.01) [G10L 15/10 (2013.01); G10L 15/14 (2013.01); G10L 19/008 (2013.01); G10L 19/0204 (2013.01); G10L 25/90 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
receiving, by one or more processors, first audio data corresponding to one or more unobstructed utterances of a user, wherein the received first audio data is associated with a received age of the user;
receiving, by one or more processors, second audio data corresponding to one or more first obstructed utterances of the user;
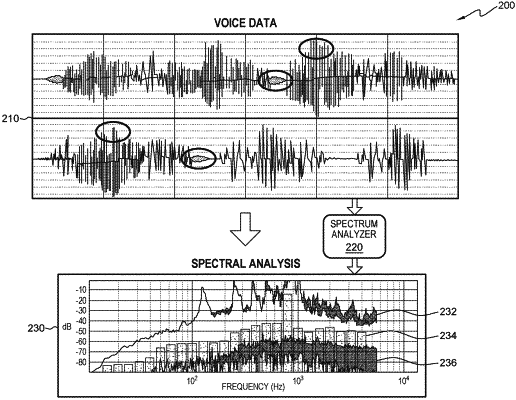
generating and storing, by one or more processors, a frequency loss model (FLM) for the user representing frequency loss between the first audio data and the second audio data at the received age of the user;
adjusting, by one or more processors, the stored FLM for the user based on changes to the user's age and stored measurements for a given age;
receiving, by one or more processors, third audio data corresponding to one or more second obstructed user utterances;
processing, by one or more processors, the third audio data using the tuned FLM to generate fourth audio data corresponding to a frequency loss mitigated version of the one or more second obstructed user utterances; and
transmitting, by one or more processors, the fourth audio data to a recipient computing device.
|