| CPC G10L 19/02 (2013.01) [G10L 25/30 (2013.01)] | 16 Claims |
|
1. An apparatus comprising:
at least one processor and a non-transitory computer-readable medium storing therein computer program code including instructions for one or more programs that, when executed by the processor, cause the processor to:
obtain audio data;
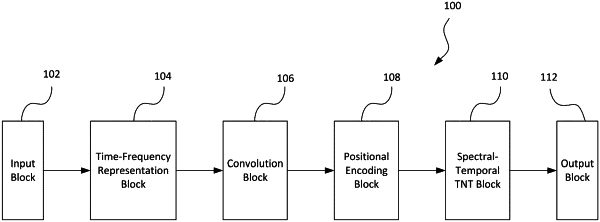
generate a time-frequency representation of the audio data to be applied as input for a transformer-based neural network model, the transformer-based neural network model including a spectral transformer and a temporal transformer;
determine spectral embeddings and first temporal embeddings of the audio data based on the time-frequency representation of the audio data, the spectral embeddings including a first frequency class token (FCT);
determine each vector of a second FCT by passing each vector of the first FCT in the spectral embeddings through the spectral transformer;
determine second temporal embeddings by adding a linear projection of the second FCT to the first temporal embeddings;
determine third temporal embeddings by passing the second temporal embeddings through the temporal transformer; and
generate music information of the audio data based on the third temporal embeddings.
|