| CPC G10L 17/14 (2013.01) [G10L 15/22 (2013.01); G10L 17/24 (2013.01); G10L 25/18 (2013.01); G10L 2015/225 (2013.01)] | 15 Claims |
|
1. A method comprising:
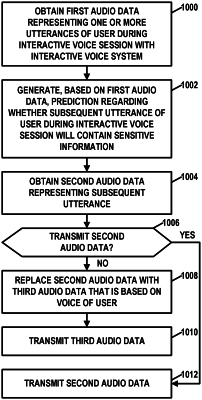
obtaining, by a computing system, first audio data representing one or more initial utterances of a user during an interactive voice session with an interactive voice system;
for each class of sensitive information in a plurality of classes of sensitive information, determining, by the computing system, based on the first audio data, a confidence score for the class of sensitive information, wherein the confidence score for the class of sensitive information indicates a level of confidence that a subsequent utterance of the user during the interactive voice session will belong to the class of sensitive information, the subsequent utterance of the user following the one or more initial utterances in time;
determining, by the computing system, a risk profile for a communication channel through which the first audio data is to be transmitted, wherein the risk profile for the communication channel includes a plurality of risk scores associated with transmitting the plurality of classes of sensitive information over the communication channel, respectively;
determining, by the computing system, that a specific class of sensitive information has the highest confidence score among the plurality of classes of sensitive information, wherein a specific risk score of the plurality of risk scores in the determined risk profile is associated with transmitting the specific class of sensitive information over the communication channel;
obtaining, by the computing system, second audio data representing the subsequent utterance of the user;
determining, by the computing system, based on a first comparison of the highest confidence score with a first predetermined threshold and a second comparison of the specific risk score with a second predetermined threshold, whether to prevent transmission of the second audio data; and
based on determining to prevent transmission of the second audio data:
generating, by the computing system, third audio data, wherein the third audio data represents a replacement utterance in the specific class of sensitive information, and the third audio is based on a voice of the user;
replacing, by the computing system, the second audio data with the third audio data; and
transmitting, by the computing system, the third audio data.
|