| CPC G10L 15/1815 (2013.01) [A61B 5/0077 (2013.01); A61B 5/1107 (2013.01); A61B 5/1114 (2013.01); A61B 5/1128 (2013.01); A61B 5/163 (2017.08); A61B 5/165 (2013.01); A61B 5/4803 (2013.01); A61B 5/7267 (2013.01); G06F 40/35 (2020.01); G06N 3/04 (2013.01); G06N 3/0455 (2023.01); G06N 3/08 (2013.01); G06T 7/70 (2017.01); G06V 20/41 (2022.01); G06V 40/168 (2022.01); G10L 15/16 (2013.01); G10L 15/183 (2013.01); G10L 15/22 (2013.01); G10L 25/57 (2013.01); G10L 25/63 (2013.01); G10L 25/90 (2013.01); G06T 2207/10016 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30201 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
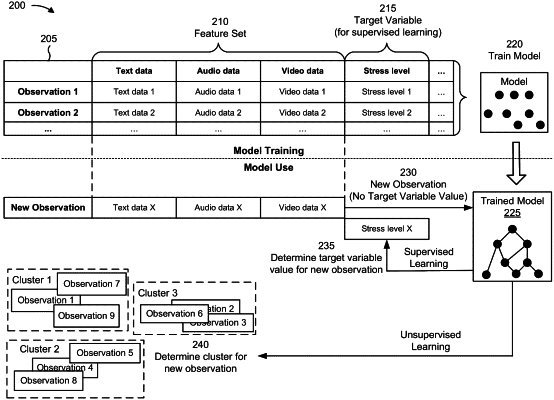
|
1. A method, comprising:
receiving, by a device and from a user device, text data identifying text input by a user of the user device, audio data identifying audio associated with the user, and video data identifying a video associated with the user;
processing, by the device, the text data, the audio data, and the video data, with a support vector machine model, to determine a stress level of the user;
processing, by the device, the text data, the audio data, and the video data, with different regression models, to determine a first depression level of the user based on the text data, a second depression level of the user based on the audio data, and a third depression level of the user based on the video data;
combining, by the device, the first depression level, the second depression level, and the third depression level to identify an overall depression level of the user;
processing, by the device, the text data, the audio data, and the video data, with a deep learning convolutional neural network model, to determine a continuous affect prediction for the user;
processing, by the device, the text data, the audio data, and the video data, with a classifier model, to determine an emotion of the user;
processing, by the device, the text data, the audio data, and the video data, with a generative pretrained transformer language model, to determine a response to the user;
utilizing, by the device, a plug and play language model to determine a context for the response, based on the response, the stress level, the overall depression level, the continuous affect prediction, and the emotion;
utilizing, by the device, one or more dialog manager models to generate contextual conversation data, based on the text data, the audio data, the video data, the response, and the context; and
performing, by the device, one or more actions based on the contextual conversational data.
|