| CPC G10L 15/063 (2013.01) [G06N 3/045 (2023.01); G10L 15/06 (2013.01); G10L 15/183 (2013.01)] | 20 Claims |
|
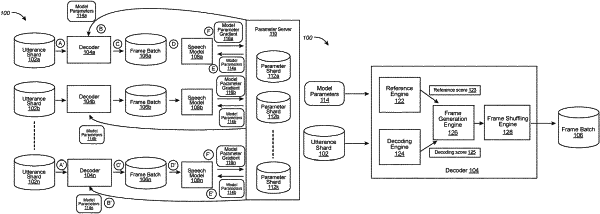
1. A computer-implemented method executed on data processing hardware that causes the data processing hardware to perform operations comprising:
receiving a replica of a neural network model;
obtaining a batch of training utterances each comprising one or more predetermined words spoken by a speaker;
training, by performing stochastic gradient descent optimization on the batch of training utterances, the replica of the neural network model to generate corresponding model parameter gradients for the neural network model; and
sending the corresponding model parameter gradients for the neural network model to a centralized server.
|