| CPC G06V 40/23 (2022.01) [G06V 10/764 (2022.01); G06V 10/7715 (2022.01); G06V 2201/12 (2022.01)] | 9 Claims |
|
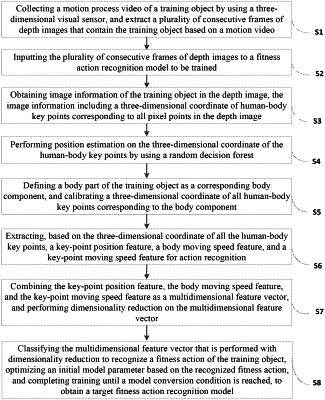
1. A fitness action recognition model, comprising an information extraction layer, a pixel point positioning layer, a feature extraction layer, a vector dimensionality reduction layer, and a feature vector classification layer, wherein
the information extraction layer is configured to obtain image information of a training object in a depth image, the image information comprising a three-dimensional coordinate of human-body key points corresponding to all pixel points in the depth image;
the pixel point positioning layer is configured to perform position estimation on the three-dimensional coordinate of the human-body key points by using a random decision forest, define a body part of the training object as a corresponding body component, and calibrate the three-dimensional coordinate of all human-body key points corresponding to the body component;
the feature extraction layer is configured to extract, based on the three-dimensional coordinate of all the human-body key points, a key-point position feature, a body moving speed feature, and a key-point moving speed feature for action recognition;
the vector dimensionality reduction layer is configured to combine the key-point position feature, the body moving speed feature, and the key-point moving speed feature as a multidimensional feature vector, and perform dimensionality reduction on the multidimensional feature vector; and
the feature vector classification layer is configured to classify the multidimensional feature vector that is performed with dimensionality reduction, to recognize a fitness action of the training object.
|