| CPC G06Q 30/0236 (2013.01) [G06Q 30/0215 (2013.01); G10L 15/22 (2013.01); G10L 15/26 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
1. A system comprising:
one or more processors; and
one or more computer-readable media storing computer-executable instructions that, when executed, cause the one or more processors to:
receive, from a client computing device in a user environment, input audio data representing speech, the speech including a query;
generate, using speech recognition processing on the input audio data, first text data corresponding to the speech;
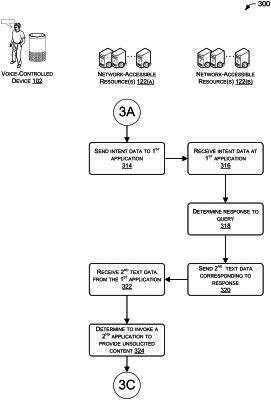
generate, using natural-language processing on the first text data, intent data associated with the query, the intent data indicative of an intent of the speech;
determine, based at least in part on the intent data, a first application that is capable of providing an answer to the query;
receive, from the first application, second text data corresponding to the answer to the query;
receive an identifier from the client computing device;
determine, using the identifier, a profile associated with the client computing device;
determine, using the profile, that the client computing device is to receive unsolicited content;
determine a network latency is less than a predefined threshold;
determine, based at least in part on the network latency being less than the predefined threshold, and that the client computing device is to receive the unsolicited content, to invoke a second application that is different than the first application;
based at least in part on the determining to invoke the second application, send, to the second application, a request to provide an unsolicited fact related to an entity referenced in the second text data, the request including at least a portion of the second text data corresponding to the answer;
receive, from the second application, third text data representing the unsolicited fact;
generate, using text-to-speech processing on the second text data, first output audio data corresponding to the answer;
generate, using text-to-speech processing on the third text data, second output audio data corresponding to the unsolicited fact, the second output audio data being for output by the client computing device after output of the first output audio data;
send, to the client computing device, the first output audio data for output in the user environment; and
send, to the client computing device, the second output audio data for output in the user environment after the first output audio data.
|