| CPC G06Q 10/06315 (2013.01) [G06Q 10/04 (2013.01)] | 21 Claims |
|
1. A computer-implemented method for forecasting a data anomaly to a supply chain, comprising:
using a number of processors to perform the steps of:
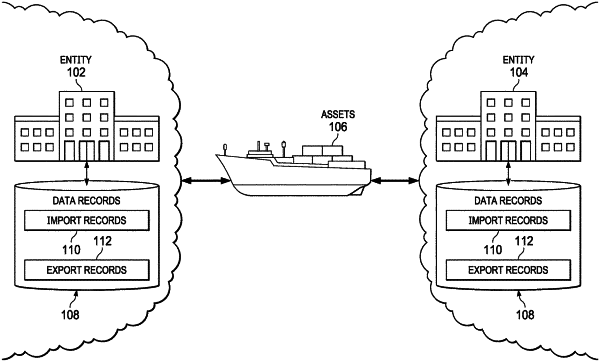
identifying a plurality of data records for a plurality of entities, the data records including import records and export records;
categorizing data fields in a plurality of data records into generic field types, wherein the generic field types comprising numeric fields, categorical fields, and date fields;
for each of a plurality of entities, constructing an entity-specific model for predicting data anomalies occurring at imports and exports of an entity based on the generic field types comprising:
generating a first set of statistics about data fields from the plurality of data records; and
controlling a data quality of the data records by identifying an anomalous record, comprising:
generating a comparison based on the first set of statistics and a first set of data records;
rejecting the first set of data record as the anomalous record when the comparison exceeds a difference threshold;
generating a set of meta-statistics according to a generic field type for data fields from the first set of statistics and the first set of data records, wherein the set of meta-statistics are statistics relates to the first set of statistics; and
generating the comparison based on the set of meta-statistics and the first set of data records, wherein comparisons generated based on the set of meta-statistics controls false positive rates to identify the anomalous record more accurately; and
replacing the first set of statistics with a second set of statistics to compare with a second set of data records;
combining the entity-specific model for each of the plurality of entities to create a global supply chain model for the plurality of entities; and
forecasting, based on the global supply chain model, the data anomaly to a supply chain that is associated with a particular entity.
|