| CPC G06F 9/4881 (2013.01) [G06F 9/30036 (2013.01); G06F 9/505 (2013.01); G06F 18/214 (2023.01); G06F 21/53 (2013.01); G06F 21/60 (2013.01); G06N 5/04 (2013.01); G06N 7/00 (2013.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. An electronic device comprising:
at least one transceiver;
at least one memory; and
at least one processor coupled to the at least one transceiver and the at least one memory, the at least one processor configured to:
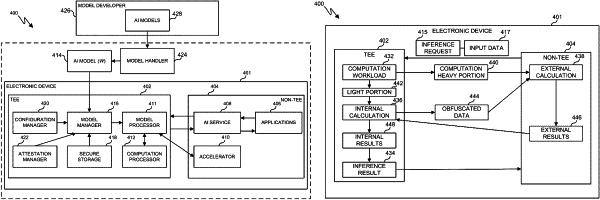
receive, via the at least one transceiver, an artificial intelligence (AI) model in a trusted execution environment (TEE) operated by the at least one processor;
receive in the TEE an inference request and input data from a source outside the TEE;
partition a calculation of an inference result between an internal calculation performed by processor resources within the TEE and an external calculation performed by processor resources outside the TEE, wherein, to partition the calculation of the inference result, the at least one processor is configured to:
split, as at least part of the internal calculation, a weight matrix of the AI model into at least two matrices in order to obfuscate data provided for the external calculation; and
provide the at least two matrices to the processor resources outside the TEE;
determine, as at least part of the external calculation, a plurality of outputs using the at least two matrices and the input data and provide the plurality of outputs to the processor resources within the TEE; and
produce the inference result based on the plurality of outputs.
|