| CPC G06F 30/392 (2020.01) [G06F 30/398 (2020.01); G06N 3/08 (2013.01)] | 20 Claims |
|
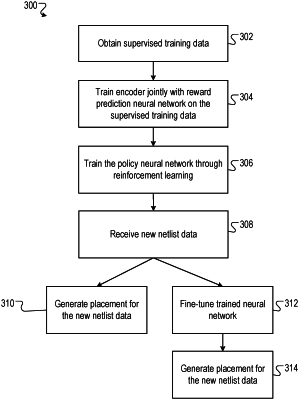
1. A method of training a node placement neural network that comprises:
an encoder neural network that is configured to, at each of a plurality of time steps, receive an input representation comprising data representing a current state of a placement of a netlist of nodes on a surface of an integrated circuit chip as of the time step and process the input representation to generate an encoder output, and
a policy neural network configured to, at each of the plurality of time steps, receive an encoded representation generated from the encoder output generated by the encoder neural network and process the encoded representation to generate a score distribution over a plurality of positions on the surface of the integrated circuit chip, the method comprising:
generating a reinforcement learning training example, comprising:
obtaining training netlist data specifying a training netlist of nodes;
generating a training placement of the training netlist of nodes using the node placement neural network, and
determining a value of a reward function that measures a quality of the training placement of the training netlist of nodes, wherein the reward function comprises a plurality of terms that each measure a respective characteristic of the training placement; and
training the policy neural network on the reinforcement learning training example through reinforcement learning.
|