| CPC G06F 3/167 (2013.01) [G06F 3/0481 (2013.01); G06F 3/0484 (2013.01); G06F 3/04886 (2013.01); G06F 40/117 (2020.01); G06F 40/143 (2020.01); G06F 40/174 (2020.01); G06F 40/30 (2020.01); G10L 15/22 (2013.01); G10L 15/26 (2013.01)] | 17 Claims |
|
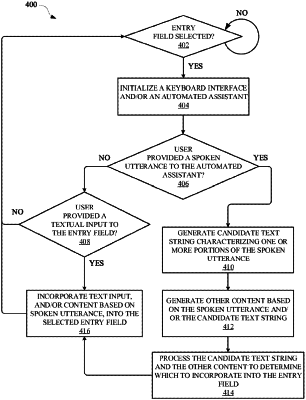
1. A method implemented by one or more processors, the method comprising:
determining that a selection of an entry field of a graphical user interface of an application that is being rendered at a computing device was provided,
wherein the computing device provides access to an automated assistant that is separate from the application and utilizes one or more speech-to-text models stored at the computing device;
receiving, subsequent to determining that the entry field was selected, a spoken utterance from a user;
generating, based on the spoken utterance, a candidate text string that characterizes at least a portion of the spoken utterance provided by the user,
wherein the candidate text string is generated using the one or more speech-to-text models stored at the computing device;
determining, by the automated assistant and based on the candidate text string, whether to incorporate the candidate text string into the entry field or whether to incorporate non-textual visual content into the entry field and in lieu of the candidate text string,
wherein determining, by the automated assistant and based on the candidate text string, whether to incorporate the candidate text string into the entry field or whether to incorporate the non-textual visual content into the entry field comprises:
determining, based on processing the candidate text string, the non-textual visual content;
identifying, based on the non-textual visual content, one or more non-textual visual content properties of the non-textual visual content; and
determining, based on comparing the one or more non-textual visual content properties of the non-textual visual content to one or more entry field properties of the entry field, whether to incorporate the candidate text string into the entry field or whether to incorporate the non-textual visual content into the entry field;
when a determination is made to incorporate the non-textual visual content into the entry field:
causing the non-textual visual content to be provided as input to the entry field of the graphical user interface, wherein the non-textual visual content is determined via performance of one or more automated assistant actions that are based on the candidate text string; and
when a different determination is made to incorporate the candidate text string into the entry field:
causing the candidate text string to be provided as input to the entry field of the graphical user interface.
|