| CPC G06F 18/2148 (2023.01) [G06F 16/383 (2019.01); G06F 18/29 (2023.01); G06V 30/413 (2022.01); G06V 30/414 (2022.01); G06V 30/416 (2022.01)] | 14 Claims |
|
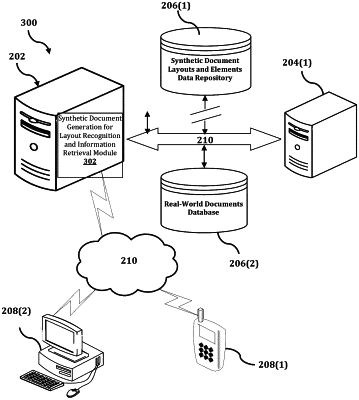
1. A method for retrieving information from a document, the method being implemented by at least one processor, the method comprising:
generating, by the at least one processor, a first synthetic document and at least a second synthetic document, the first synthetic document including a first plurality of elements and first annotation information that relates to the first plurality of elements, and the second synthetic document including a second plurality of elements and second annotation information that relates to the second plurality of elements;
training, by the at least one processor, a machine learning algorithm that is configured to detect a layout of a real-world document by using each of the first synthetic document, the first annotation information, the second synthetic document, and the second annotation information as inputs;
receiving, by the at least one processor, a first real-world document; and
generating, by the at least one processor, a modified version of the first real-world document by applying the trained machine learning algorithm to the received first real-world document,
wherein each of the first plurality of elements and the second plurality of elements is associated with a respective element type that includes at least one from among a header, a title, a section, a table, a cell, a drawing figure, a paragraph, a mathematical equation, a chart, and a footer, and
wherein the machine learning algorithm implements a Bayesian network that models relationships among a plurality of random variables that includes at least one from among a font, a border, a spacing, an alignment, a color, and a content that corresponds to each of the respective element types associated with the first plurality of elements and the second plurality of elements, and
wherein the Bayesian network defines stochastic templates with shared distributional parameters to model at least one layout structure commonality among subsets of synthetic documents.
|