| CPC G06F 18/2148 (2023.01) [G06N 20/00 (2019.01)] | 18 Claims |
|
1. A method comprising:
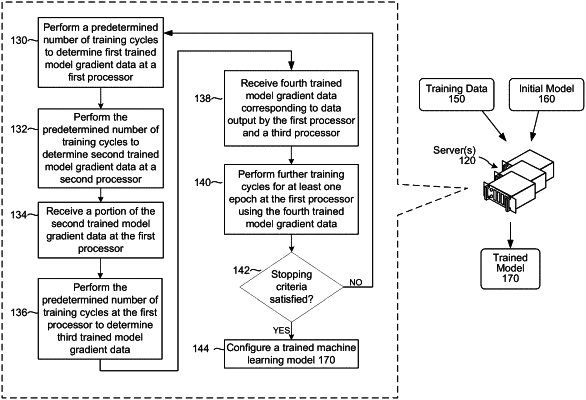
performing, by at least a first processor, at least a first training cycle for a first model to determine first gradient data, wherein the first processor is a first main processor;
determining, by the first processor and from the first gradient data, a portion of the first gradient data that satisfies a threshold;
performing, by at least a second processor, the at least first training cycle for a second model to determine second gradient data, the second processor being different than the first processor and the second gradient data being different than the first gradient data;
receiving, by the first processor and from the second processor, a portion of the second gradient data, wherein the portion of the second gradient data is determined from the second gradient data satisfying the threshold;
after receiving the portion of the second gradient data, performing, by the first processor and using the portion of the second gradient data and the portion of the first gradient data, at least a second training cycle for the first model to determine third gradient data;
after performing at least the second training cycle, coordinating an exchange of gradient data for performance of at least one training cycle by at least the first processor and a third processor by:
sending, by the first processor to at least the third processor, the third gradient data, the third processor being a second main processor and
receiving, by the first processor and from at least the third processor, fourth gradient data determined by the third processor based on performing at least the first and second training cycles for a third model; and
after receiving the fourth gradient data, performing, by the first processor and using the third gradient data and the fourth gradient data, at least a third training cycle for the first model.
|