| CPC G06F 16/285 (2019.01) [G06F 16/221 (2019.01); G06N 5/01 (2023.01)] | 20 Claims |
|
1. A method comprising:
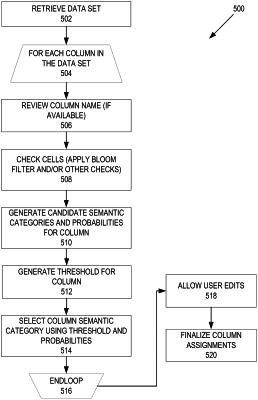
retrieving data from a data set, wherein the data is organized in a plurality of columns;
for each column in the plurality of columns:
generating one or more candidate semantic categories for the column, wherein each of the one or more candidate semantic categories is included in a plurality of semantic categories;
generating a probability for each of the one or more candidate semantic categories by applying a bloom filter to the data of the column;
creating a feature vector for the column from the one or more candidate semantic categories and the corresponding probabilities;
determining a semantic category of the column based on the feature vector;
determining a privacy category based on a designation of the semantic category; and
anonymizing the data in the column based on the privacy category to produce anonymized data, wherein the anonymizing comprises replacing more specific data in the column with less specific data based on a data hierarchy of the plurality of semantic categories that relates the more specific data to the less specific data, and wherein the less specific data reduces a likelihood that one or more data subjects are identifiable from the anonymized data; and
generating an anonymized view of the data set using the anonymized data.
|