| CPC G06F 9/45558 (2013.01) | 19 Claims |
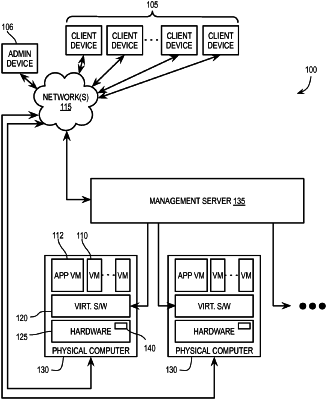
|
1. A computer implemented method, comprising processing a system call from an application running within a client virtual machine running on a first host device, wherein the processing includes:
determining that the system call is a request for a device driver to instruct a physical general-purpose graphics processing unit (GPGPU) or a co-processor to perform a function and that the request is intended for a parallel computing framework library, wherein a first appliance virtual machine provides the parallel computing library and virtualization of the GPGPU or co-processor for a plurality of virtual machines including the client virtual machine, and wherein the parallel computing framework library comprises one of a compute unified device architecture (CUDA) framework library or an open computing language (OpenCL) framework library; and
transmitting, in response to determining that the system call is intended for the parallel computing framework library, the request from the client virtual machine to the first appliance virtual machine to execute the request via a guest device pass-through that communicates directly with the GPGPU or co-processor.
|