| CPC G06F 3/04886 (2013.01) [G06F 1/1626 (2013.01); G06F 3/0233 (2013.01); G06F 3/04883 (2013.01); G06F 3/167 (2013.01); G06F 40/166 (2020.01); G06F 40/289 (2020.01); G06F 2203/0381 (2013.01); G10L 15/22 (2013.01)] | 20 Claims |
|
1. A computer-implemented method, comprising:
receiving, by a computing device, user input of a particular term via a first user input mode associated with the computing device, wherein the particular term is a textual version of the user input;
determining, at the computing device, that a first modality recognition model corresponding to the first user input mode does not recognize the particular term;
responsive to the determining that the first modality recognition model does not recognize the particular term, displaying, by the graphical user interface, one or more candidate replacement terms to replace the particular term;
detecting, by the graphical user interface and in response to the displaying of the one or more candidate replacement terms, a user indication that the textual version is a correct version of the user input;
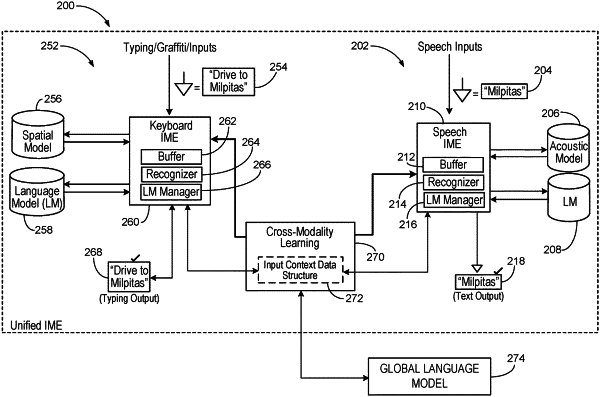
based on the user indication, adding the particular term to the first modality recognition model;
sending the particular term from the first modality recognition model to a cross-modality learning system, wherein the cross-modality learning system is configured to aggregate a plurality of parameter values based on parameter signals received from a plurality of modality recognition models, and to share the particular term and the aggregated parameter values with a second modality recognition model corresponding to a second user input mode associated with the computing device for use in cross-modality learning between the first modality recognition model and the second modality recognition model; and
updating, by the computing device and based on the particular term and the aggregated parameter values, the cross-modality learning for the second modality recognition model, wherein the updating causes the second modality recognition model to automatically recognize a subsequent user input via the second user input mode.
|