| CPC G06F 16/24568 (2019.01) [G06F 16/2462 (2019.01)] | 21 Claims |
|
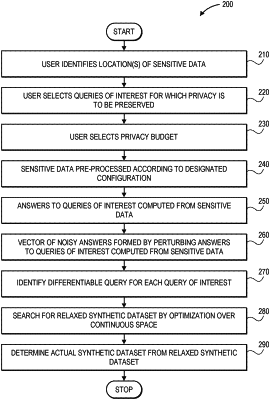
1. A method comprising:
receiving, by a first computer system from a user associated with a private dataset,
an identifier of at least one of the private dataset or a location where the private dataset is stored; and
a privacy budget,
wherein the private dataset comprises sensitive data intended for use in at least one application or function executed by one of the first computer system or a second computer system;
initializing a first synthetic dataset by the first computer system;
in a first iteration,
calculating a first set of errors by the first computer system, wherein each of the first set of errors is calculated for each of a plurality of queries based at least in part on the private dataset and the first synthetic dataset, wherein each of the first set of errors is an absolute value of a difference between an answer to one of the plurality of queries determined using the private dataset and an answer to a differentiable query corresponding to the one of the plurality of queries determined using the first synthetic dataset;
perturbing each of the first set of errors by the first computer system;
selecting a first set of queries by the first computer system, wherein each of the first set of queries is selected based at least in part on the perturbed first set of errors;
calculating answers to each of the first set of queries using the private dataset by the first computer system;
perturbing the answers to each of the first set of queries by the first computer system; and
adding each of the first set of queries to a set of selected queries by the first computer system; and
following at least the first iteration;
identifying differentiable queries corresponding to the set of selected queries by the first computer system, wherein each of the differentiable queries is differentiable over a domain including at least the first synthetic dataset;
determining answers to each of the differentiable queries corresponding to the set of selected queries using the first synthetic dataset by the first computer system;
determining a second synthetic dataset based at least in part on the answers to each of the differentiable queries corresponding to the set of selected queries and answers to each of the set of selected queries determined using the first synthetic dataset by the first computer system; and
executing the at least one application or function on at least the second synthetic dataset by the one of the first computer system or the second computer system.
|