| CPC H04W 4/38 (2018.02) [G06F 18/214 (2023.01); G06N 5/043 (2013.01); G06N 20/20 (2019.01); G06V 10/774 (2022.01); G06V 10/95 (2022.01); H04L 67/34 (2013.01)] | 18 Claims |
|
1. A distributed inference system comprising:
an end device comprising a processor configured to:
generate status information corresponding to the end device, obtain target data,
perform a first inference of the target data based on a first machine learning model and generate an inference result corresponding to the target data,
when the first inference fails, set a priority of an inference request, and
transmit the inference request, the status information and the inference result; and
a server configured to:
receive the status information and the inference result,
create a second machine learning model based on the status information and a training dataset comprising the inference result,
generate accuracy information corresponding to an accuracy of the inference result, and
transmit the second machine learning model to the end device based on the accuracy information,
wherein the server comprises:
a device manager configured to:
generate a grade of the end device based on the status information, and
calculate a priority of the end device based on the grade, and
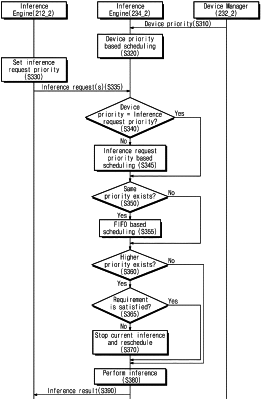
an inference engine configured to perform a second inference of the target data in response to the inference request,
wherein the grade comprises one of a first grade associated with a first criteria or a second grade associated with a second criteria, and
wherein the inference engine is configured to:
schedule the inference request based on the priority of the end device, and
when the priority of the inference request and the priority of the end device are different, schedule the inference request based on the priority of the inference request.
|