| CPC G10L 17/02 (2013.01) [G10L 17/04 (2013.01); G10L 17/18 (2013.01); G10L 25/63 (2013.01)] | 13 Claims |
|
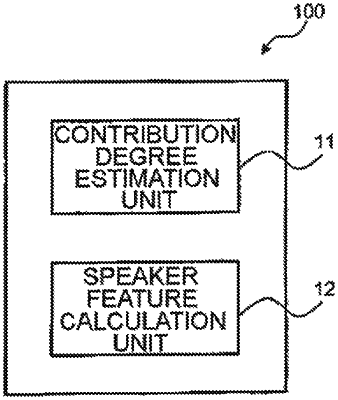
1. A speech processing device, comprising:
a processor; and
memory storing executable instructions that, when executed by the processor, causes the processor to perform as:
a contribution degree estimation unit configured to calculate a contribution degree representing a quality of a segment of a speech signal indicative of speech, the speech signal being divided into a plurality of segments; and
a speaker feature calculation unit configured to calculate a speaker feature from the speech signal, for recognizing attribute information of the speech signal, using the contribution degree as a weight of each segment of the speech signal, the speaker feature being indicative of individuality for identifying a speaker which utters the speech.
|