| CPC G06V 20/64 (2022.01) [G06F 40/10 (2020.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06T 7/0012 (2013.01); G06T 7/11 (2017.01); G06V 10/454 (2022.01); G06V 10/82 (2022.01); G16H 30/40 (2018.01); G16H 50/20 (2018.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30004 (2013.01)] | 20 Claims |
|
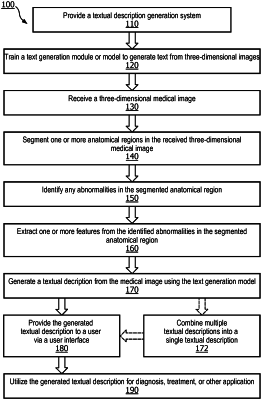
1. A method for generating a textual description of a medical image, comprising:
receiving the medical image and associated Digital Imaging and Communications in Medicine (DICOM) tags, the medical image comprising an anatomical region and a remainder of the image, the anatomical region comprising one or more abnormalities;
segmenting, using adaptive thresholding, the anatomical region in the received medical image from the remainder of the image;
identifying at least one of the one or more abnormalities in the segmented anatomical region;
extracting one or more features from the identified at least one of the one or more abnormalities using the DICOM tags;
generating, using the extracted features and a trained text generation model, the textual description of the identified at least one of the one or more abnormalities, wherein the textual description includes a description of a physical feature of the at least one of the one or more abnormalities and a description of a location of the at least one of the one or more abnormalities; and
reporting, via a user interface of the system, the generated textual description of the identified at least one of the one or more abnormalities to assist a user with evaluating the medical image.
|