| CPC G06N 5/04 (2013.01) [G06F 9/5011 (2013.01); G06N 20/00 (2019.01)] | 20 Claims |
|
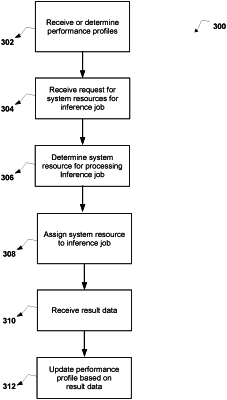
1. A computer-implemented method, comprising:
receiving or determining, with at least one processor, a plurality of performance profiles associated with a plurality of system resources, wherein each performance profile is associated with a machine learning model, wherein each performance profile for each system resource includes a latency associated with the machine learning model for that system resource, a throughput associated with the machine learning model for that system resource, and an availability of that system resource for processing an inference job associated with the machine learning model, and wherein the plurality of system resources includes at least one central processing unit (CPU) and at least one graphics processing unit (GPU);
receiving, with at least one processor, a request for system resources for the inference job associated with the machine learning model;
determining, with at least one processor, a system resource of the plurality of system resources for processing the inference job associated with the machine learning model based on the plurality of performance profiles and a quality of service requirement associated with the inference job; and
assigning, with at least one processor, the system resource to the inference job for processing the inference job, wherein the system resource assigned to the inference job executes the machine learning model associated with the inference job to process the inference job.
|