| CPC G06N 20/00 (2019.01) [G06N 5/04 (2013.01); G06F 9/45533 (2013.01)] | 20 Claims |
|
1. A method, comprising:
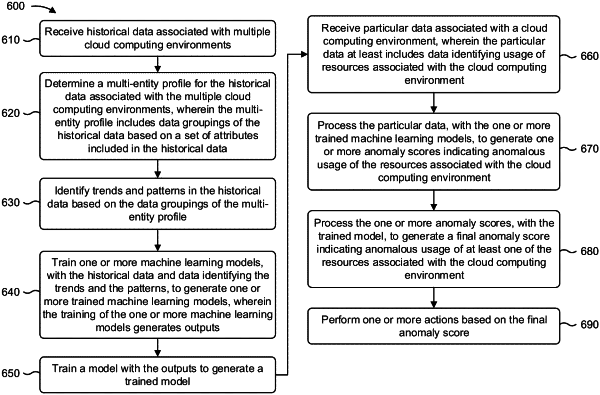
receiving, by a device, historical data associated with multiple cloud computing environments;
training, by the device, one or more machine learning models, with the historical data, to generate one or more trained machine learning models,
wherein the training of the one or more machine learning models generates outputs;
applying, by the device, weights to the outputs based on an amount of change or a percent change associated with the outputs;
generating, by the device, a super model with the outputs,
wherein the super model is first trained based on synthetic training data,
wherein the super model is trained based on combining first output of a kernel density estimation model, of the one or more machine learning models, and a second output of a quantile model of the one or more machine learning models, and
wherein the synthetic training data changes based on addition of the kernel density estimation model and the quantile model to the super model;
receiving, by the device, current data associated with a cloud computing environment, of the multiple cloud computing environments,
wherein the current data at least includes data identifying usage of resources associated with the cloud computing environment;
processing, by the device, the current data, with the one or more trained machine learning models, to generate one or more anomaly scores indicating anomalous usage of the resources associated with the cloud computing environment,
wherein processing the current data, with a discrete cosine transform signal processing model, of the one or more trained machine learning models, comprises:
analyzing, over a time period, frequency spectrums of usage data of individual virtual machines, of the resources, to identify changes in usage patterns, and
comparing outputs, generated by analyzing the frequency spectrums of usage data, with outputs from different time periods;
processing, by the device, the one or more anomaly scores, with the super model, to generate a final anomaly score indicating anomalous usage of at least one of the resources associated with the cloud computing environment,
wherein the super model applies different weights to a first anomaly score generated by the kernel density estimation model, a second anomaly score generated by the discrete cosine transform signal processing model to generate the final anomaly score; and
performing, by the device, one or more actions based on the final anomaly score.
|