| CPC G06F 9/4881 (2013.01) [G06F 9/5016 (2013.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01)] | 66 Claims |
|
1. A method of dynamically executing batches of requests on one or more execution engines running a machine-learning transformer model, comprising:
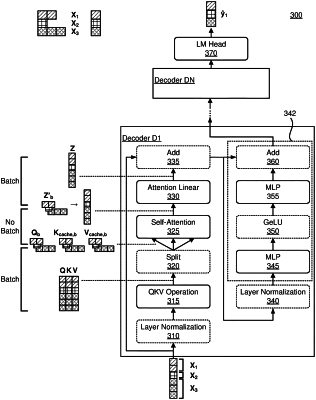
receiving, by a serving system, one or more requests for execution, the serving system including a scheduler and one or more execution engines each coupled to access a machine-learning transformer model including at least a set of decoders;
scheduling, by the scheduler, a batch of requests including the one or more requests for execution on an execution engine;
generating, by the execution engine, a first set of output tokens by applying the transformer model to a first set of inputs for the batch of requests, wherein applying the transformer model comprises applying at least one batch operation to one or more input tensors associated with the batch of requests;
receiving, by the serving system, a new request from a client device;
obtaining a sequence of input tokens for the new request;
scheduling, by the scheduler, a second batch of requests for execution on the execution engine, the second batch of requests including the new request and at least one request in the batch of requests, wherein in a second set of inputs for the second batch of requests, a length of the sequence of input tokens for the new request is different from a length of an input for the at least one request; and
generating, by the execution engine, a second set of output tokens by applying the transformer model to the second set of inputs for the second batch.
|