| CPC G06F 40/216 (2020.01) [G06F 18/214 (2023.01); G06F 18/24765 (2023.01); G06N 20/00 (2019.01)] | 16 Claims |
|
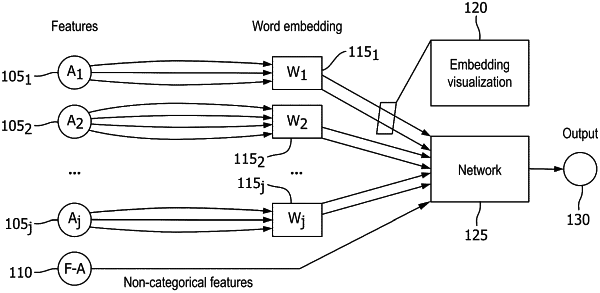
1. A machine learning model, comprising:
a categorical input feature, having a defined set of values;
a plurality of non-categorical input features;
a word embedding layer configured to convert the categorical input feature into an output in a word space having two dimensions; and
a machine learning network configured to receive the output of the word embedding layer and the plurality of non-categorical input features and to produce a machine learning model output, wherein the word embedding layer comprises coefficients that are determined by training the machine learning model and wherein converting the categorical input feature into an output in a word space having two dimensions further comprises: calculating Ki=Wi*Xi, where Ki is the output of the word embedding, Wi is the word embedding matrix, and Xi is the categorical input value.
|