| CPC G06F 16/285 (2019.01) [G06F 16/252 (2019.01); G06F 16/258 (2019.01)] | 21 Claims |
|
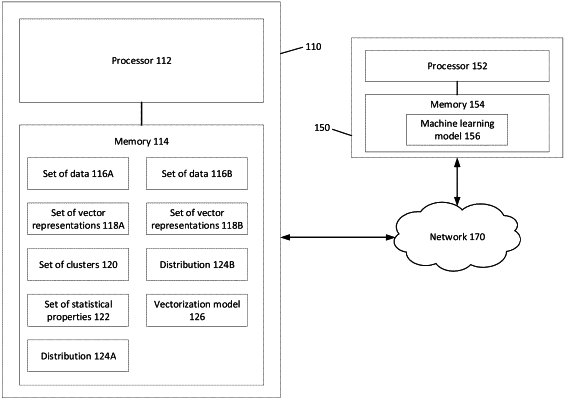
1. A method, comprising:
receiving a first set of data having dimensionality greater than a predetermined value;
generating a first set of vector representations from the first set of data using a vectorization model, the first set of vector representations having dimensionality not greater than the predetermined value;
generating a set of clusters from the first set of vector representations;
determining a statistical property associated with each cluster from the set of clusters to generate a set of statistical properties;
associating, using the set of statistical properties and to generate a distribution associated with the first set of vector representations, each vector representation from the first set of vector representations to a cluster from the set of clusters;
receiving a second set of data having dimensionality greater than the predetermined value, the second set of data different than the first set of data;
generating a second set of vector representations from the second set of data using the vectorization model, the second set of vector representations not having dimensionality greater than the predetermined value;
associating, using the set of statistical properties and to generate a distribution associated with the second set of vector representations, each vector representation from the second set of vector representations to a cluster from the set of clusters;
detecting, based on a comparison of the distribution associated with the first set of vector representations with the distribution associated with the second set of vector representations, data drift between the first set of vector representations and the second set of vector representations; and
causing transmission of a signal to cause a remedial action in response to the data drift exceeding a data drift threshold.
|