| CPC G06F 16/24568 (2019.01) [G06F 16/244 (2019.01); G06F 16/2456 (2019.01); G06F 16/24564 (2019.01)] | 24 Claims |
|
1. A method comprising:
identifying, by at least one hardware processor, a first dataset of a plurality of distributed datasets on a cloud data platform, the first dataset being associated with a first user of the cloud data platform;
identifying a semantic type for each feature of the first dataset each feature including a column of a plurality of columns of the plurality of distributed datasets;
identifying a semantic type for each feature of each dataset of the plurality of distributed datasets;
comparing semantic types, the semantic types including each identified semantic type for each feature of the first dataset and each identified semantic type for each feature of each dataset of the plurality of distributed datasets;
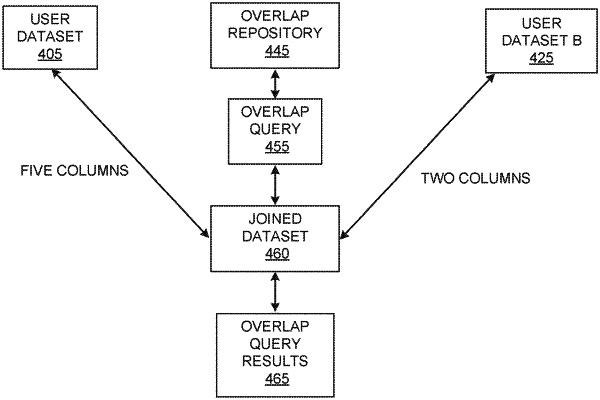
generating, based on the comparing of the semantic types, a plurality of overlap requests that are configured to output overlap datasets between the first dataset and one or more of the plurality of distributed datasets;
storing, on the cloud data platform, the overlap datasets, each of the overlap datasets including a set of common features and a set of non-common features between the first dataset and the one or more of the plurality of distributed datasets;
recommending, to the first user, a Joined dataset based on semantic types of the set of non-common features;
generating the Joined dataset including data from the first dataset and data from the one or more of the plurality of distributed datasets;
generating a results dataset by applying one or more of the plurality of overlap requests to the joined dataset; and
returning, to the first user, the results dataset.
|