| CPC H04S 7/303 (2013.01) [H04R 3/12 (2013.01); H04R 5/02 (2013.01); H04S 3/008 (2013.01); H04S 2400/01 (2013.01); H04S 2400/11 (2013.01)] | 20 Claims |
|
1. An audio augmentation system comprising:
a memory configured to store program instructions; and
one or more processors operably connected to the memory, wherein the program instructions are executable by the one or more processors to:
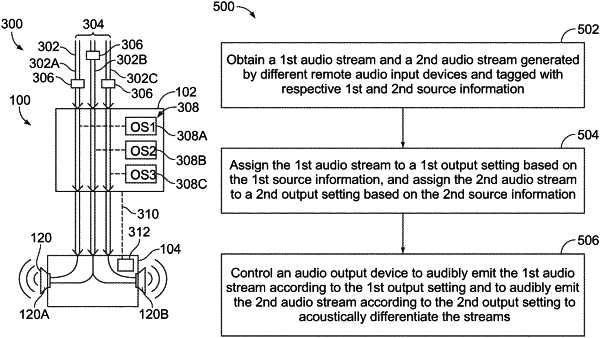
obtain a first audio stream generated by a first remote audio input device and a second audio stream generated by a second remote audio input device, wherein the first audio stream is tagged with first source information and the second audio stream is tagged with second source information, wherein the first source information identifies a first entity affiliated with at least one of the first remote audio input device or a first user that vocalizes audio captured by the first remote audio input device, and the second source information identifies a second entity affiliated with at least one of the second remote audio input device or a second user that vocalizes audio captured by the second remote audio input device;
assign the first audio stream to a first output setting based on the first entity, and assign the second audio stream to a second output setting based on the second entity, the second output setting different from the first output setting; and
control an audio output device to audibly emit the first audio stream according to the first output setting and the second audio stream according to the second output setting to acoustically differentiate the first audio stream from the second audio stream, independent of content of each of the first and second audio streams.
|
|
11. A method comprising:
obtaining a first audio stream generated by a first remote audio input device and a second audio stream generated by a second remote audio input device, wherein the first audio stream is tagged with first source information and the second audio stream is tagged with second source information, wherein the first source information identifies a first entity affiliated with at least one of the first remote audio input device or a first user that vocalizes audio captured by the first remote audio input device, and the second source information identifies a second entity affiliated with at least one of the second remote audio input device or a second user that vocalizes audio captured by the second remote audio input device;
assigning the first audio stream to a first output setting based on the first entity, and assigning the second audio stream to a second output setting based on the second entity, the second output setting different from the first output setting; and
controlling an audio output device to audibly emit the first audio stream according to the first output setting and the second audio stream according to the second output setting to acoustically differentiate the first audio stream from the second audio stream, independent of content of each of the first and second audio streams.
|
|
18. A computer program product comprising a non-transitory computer readable storage medium, the non-transitory computer readable storage medium comprising computer executable code configured to be executed by one or more processors to:
obtain a first audio stream generated by a first remote audio input device and a second audio stream generated by a second remote audio input device;
input the first audio stream to a machine learning algorithm configured to monitor the first audio stream and output first source information that characterizes the first audio stream;
input the second audio stream to the machine learning algorithm that is configured to monitor the second audio stream and output second source information that characterizes the second audio stream;
assign the first audio stream to a first output setting based on the first source information output by the machine learning algorithm, and assign the second audio stream to a second output setting based on the second source information output by the machine learning algorithm, the second output setting different from the first output setting; and
control an audio output device to audibly emit the first audio stream according to the first output setting and the second audio stream according to the second output setting to acoustically differentiate the first audio stream from the second audio stream, independent of content of each of the first and second audio streams.
|