| CPC G10L 15/22 (2013.01) [G06V 40/161 (2022.01); G10L 15/25 (2013.01); G10L 15/26 (2013.01); H04M 1/72 (2013.01); B60R 16/0373 (2013.01); G01C 21/3608 (2013.01); G01C 21/3629 (2013.01)] | 16 Claims |
|
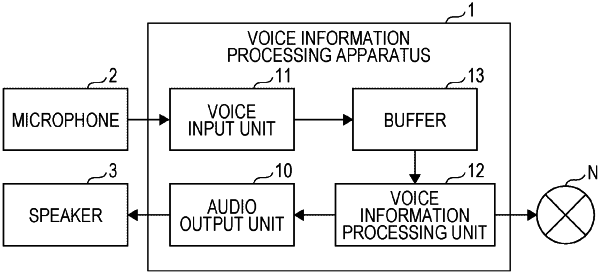
1. A voice information processing apparatus, comprising:
a voice input unit configured to input a voice;
an audio output unit configured to output utterance content of the voice; and
a voice information processing unit connected to a camera configured to photograph a face of a user;
wherein the voice information processing unit is configured to:
convert the voice input by the voice input unit into text during a voice reception period that is a period in which an uttered voice to be converted into text is received from a user;
monitor whether or not the face of the user moves in a predetermined mode based on the photographed result of the camera;
determine that the user is interrupted based on the monitoring that the face of the user moves in the predetermined mode and based on the user not uttering for a predetermined time or longer while the utterance of the user is sequentially converted into text during the voice reception period, and in response to determining that the user is interrupted based on both determinations, automatically output the utterance content of the voice to the audio output unit; and
after automatically outputting the utterance content of the voice to the audio output unit in response to determining that the user is interrupted based on both determining that the face of the user moves in the predetermined mode and based on the user not uttering for a predetermined time or longer, automatically return to convert the voice input by the voice input unit into text during a subsequent voice reception period in which uttered voice received from the user is converted into text.
|