| CPC G10L 15/16 (2013.01) [G10L 15/063 (2013.01); G10L 15/197 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01); G10L 25/21 (2013.01); G10L 2015/0635 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
1. A method for recognizing speech, the method comprising:
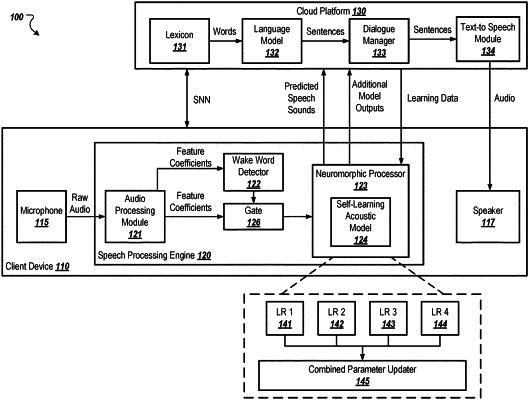
receiving, a trained acoustic model implemented as a spiking neural network (SNN) on a neuromorphic processor of a client device, a set of feature coefficients that represent acoustic energy of input audio received from a microphone communicably coupled to the client device, wherein the acoustic model is trained to predict speech sounds based on input feature coefficients;
generating, by the acoustic model, output data indicating predicted speech sounds corresponding to the set of feature coefficients that represent the input audio received from the microphone;
updating, by the neuromorphic processor, one or more parameters of the acoustic model using one or more learning rules and the predicted speech sounds of the output data, wherein at least one learning rule is configured to update parameters of the acoustic model based on each speech recognition event for which the acoustic model generates a prediction of speech sounds; and
initiating an action based on the output data.
|