| CPC G06N 5/01 (2023.01) [G06F 18/2155 (2023.01); G06F 18/22 (2023.01); G06F 18/231 (2023.01); G06F 18/24 (2023.01); G06F 18/29 (2023.01); G06N 20/20 (2019.01)] | 14 Claims |
|
1. A method for decoding random forest models, comprising:
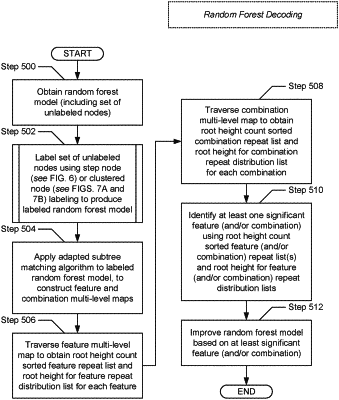
obtaining a random forest model comprising a set of unlabeled nodes, wherein the random forest model is a machine learning algorithm;
labeling the set of unlabeled nodes using a tree node labeling algorithm, to produce a labeled random forest model, wherein the tree node labeling algorithm utilizes step node labeling, wherein the step node labeling generates labels for the set of unlabeled nodes based on threshold steps for features presented in the random forest model, wherein the threshold steps refer to a class interval size in a distribution of feature values based on the random forest model;
applying, to the labeled random forest model, an adapted subtree matching algorithm to construct a feature multi-level map, wherein the adapted subtree matching algorithm is a subtree matching algorithm that has been adapted, wherein the feature multi-level map is a first nested array, wherein the first nested array is utilized to track a root height distribution of feature repeats in the labeled random forest model;
traversing the feature multi-level map to obtain a sorted feature repeat list and a set of root heights for feature repeat distribution lists, wherein the sorted feature repeat list reflects a first frequency that a unique feature appears in the random forest model wherein the feature repeat distribution list is a first distribution list for the unique feature in the random forest model;
identifying a significant feature of the random forest model using at least one of a group consisting of the sorted feature repeat list and the set of root height for feature repeats distribution lists;
improving the random forest model at least based on the significant feature, wherein improving comprises:
collecting a set of data samples biased to the significant feature; and
optimizing, thereby improving a performance of, the random forest model using the set of data samples, wherein optimizing includes validating the random forest model through supervised learning.
|