| CPC G06N 3/063 (2013.01) [G06F 7/50 (2013.01); G06F 7/5443 (2013.01); G06N 3/0464 (2023.01)] | 5 Claims |
|
1. A method, comprising:
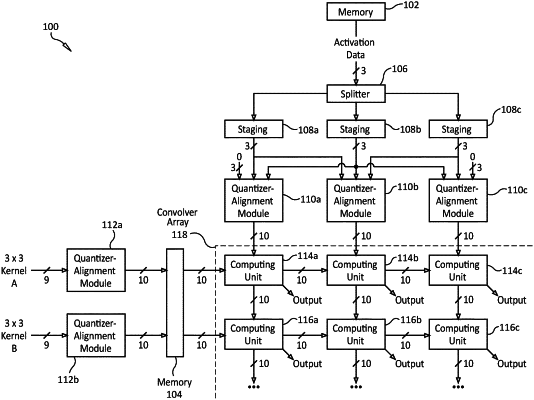
receiving, by a first computing unit, a first plurality of quantized activation values represented by a first plurality of activation mantissa values and a first activation exponent shared by the first plurality of activation mantissa values, wherein the first plurality of quantized activation values is a quantized representation of a first matrix with values
 receiving, by the first computing unit, a first quantized convolutional kernel represented by a first plurality of kernel mantissa values and a first kernel exponent shared by the first plurality of kernel mantissa values;
computing, by the first computing unit, a first dot product of the first plurality of activation mantissa values and the first plurality of kernel mantissa values;
computing, by the first computing unit, a first sum of the first shared activation exponent and the first shared kernel exponent;
receiving, by a second computing unit, the first plurality of quantized activation values;
receiving, by the second computing unit, a second quantized convolutional kernel represented by a second plurality of kernel mantissa values and a second kernel exponent shared by the second plurality of kernel mantissa values;
computing, by the second computing unit, a second dot product of the first plurality of activation mantissa values and the second plurality of kernel mantissa values;
computing, by the second computing unit, a second sum of the first shared activation exponent and the second shared kernel exponent;
receiving, by a third computing unit, a second plurality of quantized activation values represented by a second plurality of activation mantissa values and a second activation exponent shared by the second plurality of activation mantissa values, wherein the second plurality of quantized activation values is a quantized representation of a second matrix with values
 wherein six of the values of the first matrix are identical to six of the values of the second matrix;
receiving, by the third computing unit, the first quantized convolutional kernel;
computing, by the third computing unit, a third dot product of the second plurality of activation mantissa values and the first plurality of kernel mantissa values;
computing, by the third computing unit, a third sum of the second shared activation exponent and the first shared kernel exponent;
receiving, by a fourth computing unit, the second plurality of quantized activation values;
receiving, by the fourth computing unit, the second quantized convolutional kernel;
computing, by the fourth computing unit, a fourth dot product of the second plurality of activation mantissa values and the second plurality of kernel mantissa values; and
computing, by the fourth computing unit, a fourth sum of the second shared activation exponent and the second shared kernel exponent,
wherein the first plurality of quantized activation values are received by the first and second computing units, but not by the third and fourth computing units,
wherein the second plurality of quantized activation values are received by the third and fourth computing units, but not by the first and second computing units,
wherein the first quantized convolutional kernel is received by the first and third computing units, but not by the second and fourth computing units, and
wherein the second quantized convolutional kernel is received by the second and fourth computing units, but not by the first and third computing units.
|