| CPC G06N 20/00 (2019.01) [G06F 16/2365 (2019.01); G06Q 30/0275 (2013.01)] | 32 Claims |
|
1. A real-time parallelized data integrity preservation apparatus, comprising:
at least one memory;
a component collection stored in the at least one memory;
any of at least one processor disposed in communication with the at least one memory, the any of at least one processor executing processor-executable instructions from the component collection, the component collection storage structured with processor-executable instructions comprising:
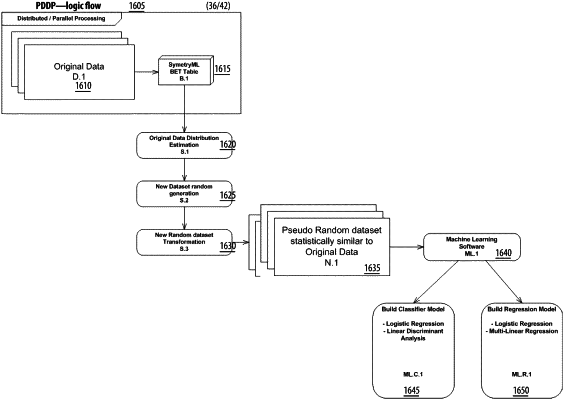
obtain an original dataset data structure from a plurality of data source types using a symmetry machine learning component;
determine, based on the obtained original dataset data structure, an appropriate type of symmetry machine learning basic element table;
generate original data distribution estimation data structure from the original dataset data structure;
generate new dataset random generation data structure from the original data distribution estimation data structure;
generate new random dataset transformation data structure by factorizing the new dataset random generation data structure;
transform the original dataset data structure with the symmetry machine learning basic element table and the new random dataset transformation data structure into a pseudo random dataset data structure;
provide the pseudo random dataset data structure to a machine learning component; and
generate build classifier and build regression structures from the machine learning component.
|