| CPC G06F 9/5077 (2013.01) [G06F 16/2379 (2019.01)] | 23 Claims |
|
1. A method for generating and maintaining computing resources comprising:
receiving a data set;
receiving one or more processing instructions corresponding to the received data set and comprising one or more processing tasks to be performed on the received data set;
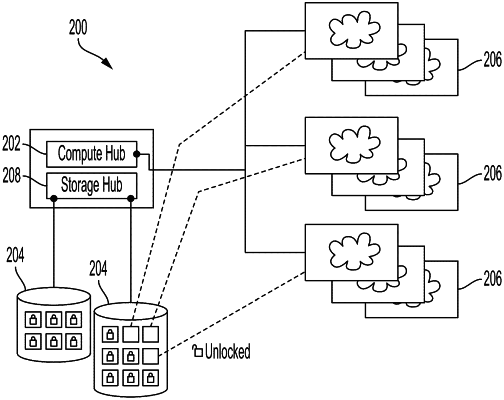
generating one or more data containers within a first computing resource based on the received one or more processing instructions, wherein the first computing resource is a persistent computing resource;
storing the data set in the one or more containers within the first computing resource;
selecting, by one or more programs running in a computing hub, one or more cloud-based computing platforms based on a type of processing comprising a data operation that is to be performed on the data set and based on an efficiency of performing the type of processing at the one or more cloud-based computing platforms, wherein the type of processing is indicated by the one or more processing instructions, wherein the one or more cloud-based computing platforms are selected from a plurality of cloud-based computing platforms each comprising respective computing resources, and wherein the selecting comprises:
analyzing, by the one or more programs, the one or more processing instructions to determine a type of processing indicated by the one or more processing instructions; and
determining, by the one or more programs, that the determined type of processing is more efficiently handled using computing resources of the one or more cloud-based computing platforms as compared to using the computing resources of one or more other cloud-based computing platforms in the plurality of cloud-based computing platforms;
generating a second computing resource on the selected one or more cloud-based computing platforms based on the received one or more processing instructions, wherein the second computing resource is an ephemeral node and is executed externally to the first computing resource;
accessing the stored data set of the first computing resource for processing by the second computing resource;
determining a processing usage of the second computing resource; and
modifying the second computing resource based on its determined processing usage.
|