| CPC G06F 40/295 (2020.01) [G06F 16/90332 (2019.01); G06F 40/40 (2020.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06F 40/205 (2020.01); G06F 40/30 (2020.01)] | 20 Claims |
|
1. A computer-implemented method of natural language processing, comprising:
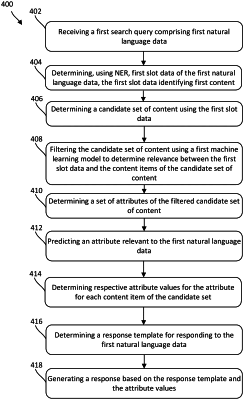
receiving a first search query comprising first natural language data;
determining, using a named entity recognition component, first slot data of the first natural language data, the first slot data identifying a first class of content;
determining a set of other content by using the first slot data as a second search query of a search engine, the set of other content comprising a plurality of items related to the first slot data;
determining, using a first machine learning model, a first relevance score between a first item of the plurality of items and the first slot data;
determining a set of attributes of the first item, wherein each attribute of the set of attributes is associated with a respective attribute value for the first item;
inputting the first natural language data into a second machine learning model;
determining, by the second machine learning model, a respective second relevance score between the first natural language data and each attribute of the set of attributes;
selecting a first attribute among the set of attributes using the second relevance score of the first attribute;
determining the attribute value associated with the first attribute for the first item;
selecting a response template to respond to the first natural language data;
generating second natural language data according to the response template, the second natural language data comprising a response to the first natural language data, the second natural language data including the attribute value associated with the first attribute for the first item;
generating, using a text-to-speech (TTS) component, first audio data representing the second natural language data; and
outputting the first audio data.
|