| CPC G06F 3/013 (2013.01) [G10L 15/16 (2013.01); G10L 15/24 (2013.01)] | 20 Claims |
|
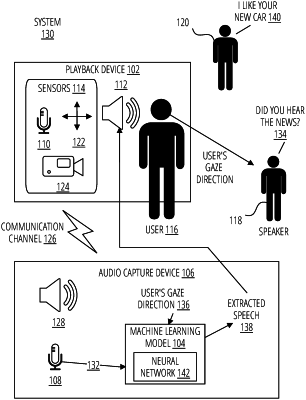
1. A method performed by at least one processor of an audio capture device, comprising:
receiving, by the at least one processor, a plurality of microphone signals from a plurality of microphones that are at different locations of the audio capture device, at least two microphone signals comprising a pilot signal produced by a transducer of a playback device that is separate from the audio capture device;
determining, by the at least one processor, a gaze of a user who is wearing the playback device, the gaze of the user being determined relative to the audio capture device and based on a time difference of arrivals of the pilot signal based on the at least two microphone signals;
extracting, by the at least one processor, speech that correlates to the gaze of the user, from the plurality of microphone signals, by applying the plurality of microphone signals and the gaze of the user to a machine learning model; and
causing, by the at least one processor, the audio capture device to send the extracted speech to the playback device for playback.
|