| CPC G06F 18/2148 (2023.01) [G06F 18/251 (2023.01); G06F 40/30 (2020.01); G06T 9/002 (2013.01); G06V 30/262 (2022.01); G06N 3/08 (2013.01)] | 20 Claims |
|
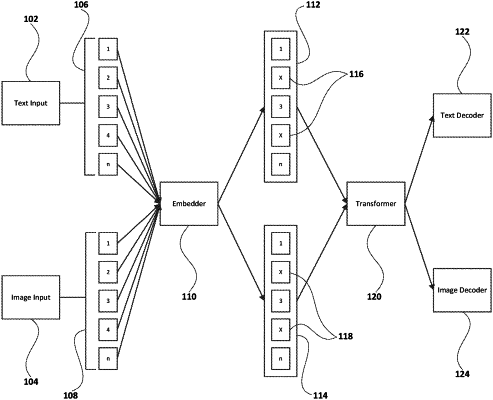
1. A computer-implemented method, comprising:
generating a first set of embeddings based on a text input;
generating a second set of embeddings corresponding to an input image;
associating the first set of embeddings with the second set of embeddings;
generating, based at least in part on the first set of embeddings and the second set of embeddings, a third set of embeddings including one or more placeholder values associated with one or more values removed from the first set of embeddings and the second set of embeddings;
predicting one or more values corresponding to known values associated with the first set of embeddings and the second set of embeddings; and
reconstructing at least one of the text input and the image input based, at least in part, on replacing the one or more placeholder values with the one or more predicted values.
|