| CPC H04L 41/044 (2013.01) [H04L 41/0836 (2013.01); H04L 41/18 (2013.01); H04L 41/5051 (2013.01); H04L 67/1031 (2013.01); H04L 67/51 (2022.05)] | 15 Claims |
|
1. A method of managing and running a hierarchical computing network, comprising:
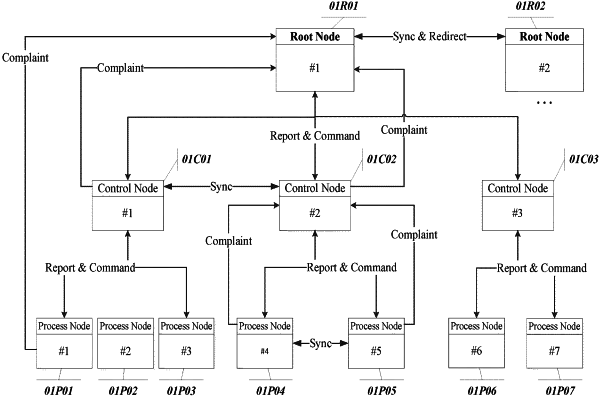
(i) providing a hierarchical computing network that delivers a network service to a client, wherein the network comprises multiple hierarchical layers of service nodes, each delivers a node service, wherein all said service nodes are accessible to the client, and wherein said multiple hierarchical layers of service nodes include least a center node layer, a region node layer, and a storage node layer; or at least a root node layer, a control mode layer, and a process node layer, for spreading out the burden of computation, network traffic and data storage to as many nodes as possible and making the entire network dynamically scalable;
(ii) grouping two or more service nodes at a same hierarchical level into a service node group (i.e. a DRU), wherein each service node provides a redundancy to service node(s) in the same service node group; and
(iii) said client scaling a network service uptime of the hierarchical computing network by (1) adding a service node to the service node group (or the DRU) to linearly increase the network service uptime or (2) subtracting a service node from the service node group (or the DRU) to linearly decrease the network service uptime, and customizing the network service uptime to meet said client's specific need; wherein said client is provided with knowledge of service nodes in a DRU, and is equipped with capability of switching to a next service node in the DRU when a previous one fails to deliver the node service.
|