| CPC G10L 15/16 (2013.01) [G10L 15/065 (2013.01); G10L 15/1815 (2013.01); G10L 15/183 (2013.01); G10L 2015/088 (2013.01)] | 20 Claims |
|
1. A system comprising:
at least one processor; and
at least one memory device coupled with the processor;
the at least one processor configured to:
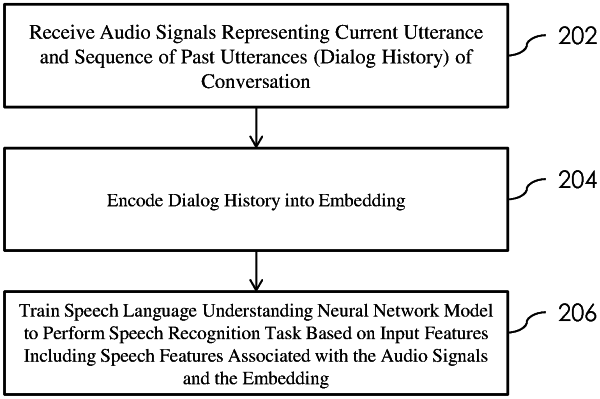
receive audio signals representing a current utterance in a conversation and a dialog history including at least information associated with past utterances corresponding to the current utterance in the conversation;
encode the dialog history into an embedding, wherein a span of the dialog history is used in encoding the dialog history;
generate input features for a spoken language understanding neural network model by appending the embedding of the dialog history to acoustics features of the audio signals; and
train the spoken language understanding neural network model to perform a spoken language understanding task based on the input features, wherein an input layer of the spoken language understanding neural network model is expanded to receive both the acoustic features of the current utterance and embedding feature dimensions of the embedding representing the dialog history, wherein network parameters associated with expanded part of the input layer are randomly initialized,
wherein the embedding feature dimensions include at least types of the past utterances classified into dialog action classification tasks, wherein the dialog action classification tasks are classified using a trained multi-label binary classification task model.
|