| CPC G06V 10/806 (2022.01) [G06V 10/54 (2022.01); G06V 10/768 (2022.01); G06V 10/7715 (2022.01)] | 12 Claims |
|
1. A counterfactual context-aware texture learning network system, comprising:
a camera configured to capture an input image;
a processor configured to perform camouflaged object detection on the input image; and
a memory configured to store a texture-aware refinement module (TRM), a context-aware fused module (CFM), and a counterfactual intervention module (CIM);
wherein the processor is configured to execute program instructions of the TRM, the CFM, and the CIM;
the TRM is configured to extract dimension features from the input image;
the CFM is configured to infuse multi-scale contextual features;
the CIM is configured to identify a camouflaged object with counterfactual intervention via the processor;
the TRM comprises:
a receptive field block (RFB) configured to expand a receptive field and extract texture features; and
a position attention module (PAM) and a channel attention module (CAM) configured to further refine texture-aware features and obtain discriminant feature representation;
the RFB comprises five branches bk, (k=1,2,3,4,5), each branch of the five branches comprising a 1×1 convolution operation to reduce a channel size to 64;
each branch where k>2 further comprises a 1×(2i−1) convolutional layer, a (2i−1)×1 convolutional layer, and a (2i−1)×(2i−1) convolutional layer, with a dilation rate of (2i−1), where i=k−1;
each branch where k>1 is concatenated, input into a second 1×1 convolution operation, and added with a branch of the five branches where k=1;
a result of the RFB is input into a Rectified Linear Unit (ReLU) activation function to obtain an output feature fi′∈
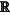 C×H×W, where C, H and W represent a channel number, a channel height, and a channel width, respectively; C×H×W, where C, H and W represent a channel number, a channel height, and a channel width, respectively;the output feature f′ is input into the PAM and the CAM,
the PAM is configured to:
obtain three feature maps B, C, and D through three convolution layers, where {B, C, and D}∈
C×H×W, and the three feature maps are reshaped to C×N; andmultiply the transpose of B by C, and perform a softmax layer to calculate the spatial attention map sa∈
N×N: where saij denotes the jth position's impact on the ith position;
a loss function L=LBCEW+LIoUW is used to train the counterfactual context-aware texture learning network system to learn effective textures, where LBCEW is the weighted binary cross entropy (BCE) loss which restricts each pixel, and Lou is a weighted intersection-over-union (IoU) loss that focuses on a global structure; and
a total loss is formulated as:
Ltotal=L(Y,y)+λL(Yeffect,y) (2)
where y is a ground truth, λ=0:1, L(Y, y) are main clues which learn general texture features, Y is a prediction of the main clues, and λL(Yeffect, y) is a counterfactual term that penalizes a wrong prediction affected by contextual biases;
thereby performing the camouflaged object detection in the input image with enhanced accuracy.
|