| CPC G06T 7/0012 (2013.01) [G06F 18/211 (2023.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06T 3/02 (2024.01); G06T 5/50 (2013.01); G06V 10/774 (2022.01); G06V 10/82 (2022.01); G06V 20/597 (2022.01); G06V 40/168 (2022.01); G06V 40/171 (2022.01); G06V 40/172 (2022.01); G06V 40/20 (2022.01)] | 12 Claims |
|
1. An image processing method, comprising:
obtaining a face image;
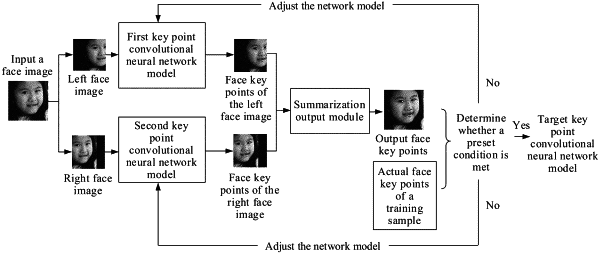
separately obtaining a left face image and a right face image based on the face image, wherein sizes of the left face image and the right face image are the same as a size of the face image;
inputting the left face image into a first target key point convolutional neural network model, and outputting coordinates of a first left face key point, wherein the first target key point convolutional neural network model is obtained after a first key point convolutional neural network model is trained by using a training left face image having key point information;
inputting the right face image into a second target key point convolutional neural network model, and outputting coordinates of a first right face key point, wherein the second target key point convolutional neural network model is obtained after a second key point convolutional neural network model is trained by using a training right face image having key point information; and
obtaining coordinates of a face key point of the face image based on the coordinates of the first left face key point and the coordinates of the first right face key point, wherein obtaining the coordinates of the face key point of the face image based on the coordinates of the first left face key point and the coordinates of the first right face key point comprises:
determining a first affine transformation matrix based on the coordinates of the first left face key point;
obtaining a corrected left face image based on the first affine transformation matrix and the left face image;
inputting the corrected left face image into a third target key point convolutional neural network model, and outputting corrected coordinates of the first left face key point;
obtaining coordinates of a second left face key point based on the corrected coordinates of the first left face key point and an in verse transformation of the first affine transformation matrix; and
obtaining the coordinates of the face key point of the face image based on the coordinates of the second left face key point and the coordinates of the first right face key point.
|