| CPC G06F 9/48 (2013.01) [G06F 9/3001 (2013.01); G06F 9/30036 (2013.01); G06F 9/3004 (2013.01); G06F 9/383 (2013.01)] | 20 Claims |
|
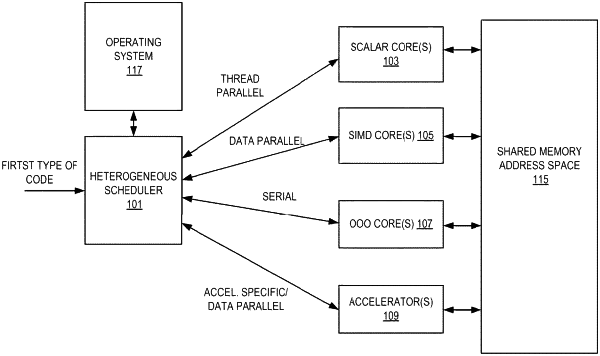
10. An integrated circuit comprising:
a first plurality of cores comprising a first microarchitecture;
a second plurality of cores comprising a second microarchitecture different from the first microarchitecture;
an interconnect coupled to the first and second plurality of cores; and
an accelerator coupled to the interconnect, the accelerator to perform matrix processing operations, the accelerator comprising:
an array of multiply-accumulate units operable in response to multiply-accumulate instructions to perform multiply-accumulate operations with a first plurality of data elements of a first matrix and a second plurality of data elements of a second matrix,
a plurality of memories associated with the array of multiply-accumulate units, the plurality of memories to store the first plurality of data elements and the second plurality of data elements,
each multiply-accumulate unit in the array of multiply-accumulate units comprising:
multiplication circuitry to multiply each data element of a subset of the first plurality of data elements with a corresponding data element of a subset of the second plurality of data elements to generate a corresponding plurality of products; and
adder circuitry to add the plurality of products to generate a corresponding result data element of a plurality of result data elements,
wherein at least one core of the first plurality of cores or the second plurality of cores is configured to execute program code to schedule the matrix processing operations.
|