| CPC G06F 16/2477 (2019.01) [G06F 11/3419 (2013.01); G06F 16/22 (2019.01); G06F 16/254 (2019.01); G06F 16/258 (2019.01)] | 20 Claims |
|
1. A computer-implemented method for ingesting, and transforming a file into a searchable state, the method comprising:
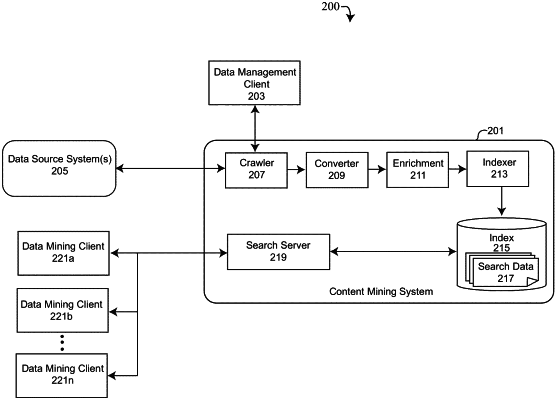
ingesting, by a processor, the file from a data source system storing the file, wherein a crawler accesses the data source system and retrieves the file based on an automated configuration to ingest one or more files associated with the data source system;
extracting, by the processor, text data and metadata from the file being ingested, including field names and values;
enriching, by the processor, the extracted text data by adding context to the extracted text data, wherein the context is selected from the group consisting of a part of speech, a descriptive tag, a keyword, a classification, and a sentiment;
identifying, by the processor, whether the file is divisible into a plurality of divided elements, based on the file type of the file being ingested, where each of the plurality of divided elements are treated as independent data;
for each file that is identified as divisible based on the file type, transforming, by the processor, the file into the searchable state by:
dividing, by the processor, the file into the plurality of divided elements;
generating, by the processor, an estimate of ingestion time (G) for each of the divided elements of the file, wherein the estimated ingestion time considers a number of the divided elements in the file, an amount of data included in the divided elements of the file, a start time of ingestion of the file, and an ingestion time estimated with a maximum number of users using computing resources simultaneously;
scaling, by the processor, the computing resources up or down based on the generated estimate of the ingestion time and the maximum number of users; and
indexing, by the processor, the text data and metadata extracted from the file as search data, to an index and inserting the estimate of ingestion time for each of the divided elements of the file into an internal field of the search data of the file being indexed.
|