| CPC G06F 16/951 (2019.01) [G06F 18/2415 (2023.01); G06F 40/279 (2020.01)] | 8 Claims |
|
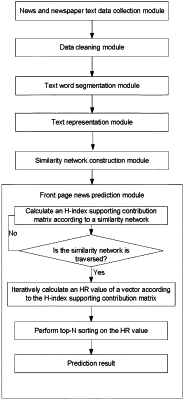
1. A front page news prediction and classification method, comprising the following steps: constructing a news network topology by using news text data;
inputting keywords to be queried by means of a user interface, collecting web pages on the Internet based on the keywords;
compiling a web crawler by using an object-oriented programming language Python, loading the web crawler into a news and newspaper text data collection module;
storing collected news text information on the web pages, by the news and newspaper text data collection module, in a local database;
performing data cleaning, by a data cleaning module, on original data obtained from a website;
performing word segmentation, by a text word segmentation module, on the cleaned data by using Jieba;
performing vector representation, by a text representation module, by using a Doc2Vec representation algorithm, so as to convert each news text into a low-dimensional text feature vector with a high amount of information;
calculating the similarity between news, by a similarity network construction module, by using a locality-sensitive hashing (LSH) algorithm, so as to obtain a similarity matrix;
constructing a news similarity network by taking the similarity matrix obtained by LSH calculation as an adjacent matrix of a news related network;
introducing an H index into a PageRank algorithm by a front page news prediction module, calculating an H-index supporting contribution matrix according to the similarity network;
determining whether the similarity network is traversed, if the similarity network is traversed, iteratively calculating an HR value of the vector according to the H-index supporting contribution matrix;
performing weight sorting on the news by using the HR value, and predicting top-N pieces of news as front page news;
wherein, the keywords are keywords of the web pages;
Jieba is a Chinese text segmenter in Python;
the front page news prediction module performs weight sorting on the news, predicts top-N pieces of news as front page news, and calculates the value of the ith row and the jth column of the H-index supporting contribution matrix according to the similarity network:
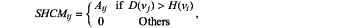 vj∈N(vi), wherein, Aif represents the value of the ith row and the jth column of the adjacent matrix of the network, vi represents a target node, vi represents a node in a domain to which vi belongs, D(vj) represents a degree of the node vi in an adjacent domain, and H(vi) represents an H index of the target node vi;
after traversing and calculating the similarity network, the front page news prediction module iteratively calculates an HR value of the vector according to the proportion of the node vf the network GSHCM, represented by an adjacency function l(vi,vj), in the total number of nodes in the v; domain NSHCM (vi) and the H-index supporting contribution matrix:
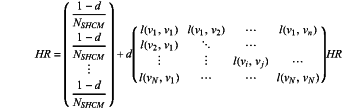 wherein, d represents a damping coefficient, and it is defined that d=0.85, NSHCM(vi) represents the domain of the node vi in the network GSHCM, DSHCH(vj) represents the degree of the node vj in the network GSHCM, Sort, represents the ith element in a sorting sequence obtained on the basis of a certain sorting algorithm, and N represents a prediction length of Top-N prediction.
|