| CPC G06F 16/2272 (2019.01) [G06F 16/27 (2019.01)] | 20 Claims |
|
1. A computer implemented method for managing datasets for a histogram, the computer implemented method comprising a number of processing units in a computer:
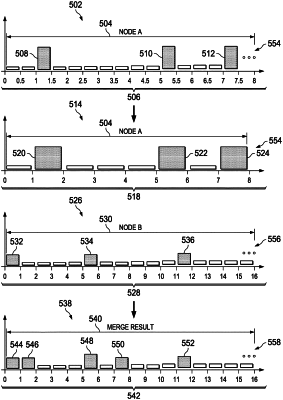
determining a first span for first bins containing first datapoints in a first dataset in the datasets, wherein the first span is determined based on a first distribution of the first datapoints in the first dataset and a desired number of bins;
adding a datapoint to the first datapoints in the first dataset, wherein the first distribution of the first datapoints has a lower bound and an upper bound comprising the first datapoints;
adjusting the lower bound and the upper bound for the first distribution of the first datapoints with the datapoint to form an adjusted distribution for the first datapoints;
determining a second adjusted span for the first dataset based on the adjusted distribution and the desired number of bins;
adjusting the first bins based on the adjusted distribution and the second adjusted span to form an adjusted first bins containing the first datapoints;
adjusting a second span for second bins containing second datapoints in a second dataset in the datasets to form an adjusted span that matches the first span for the first bins, wherein the second span is determined based on a second distribution of the second datapoints in the second dataset, and wherein the second distribution differs from the first distribution; and
merging the first datapoints in the first bins having the first span with the second datapoints in the second bins having the adjusted span to form a merged dataset for the histogram.
|