| CPC G06F 16/2237 (2019.01) [G06F 16/2264 (2019.01); G06F 16/93 (2019.01); G06F 16/953 (2019.01)] | 15 Claims |
|
1. A method for a textual document search engine, comprising:
initializing the textual document search engine, by
inputting, into a memory, a plurality of documents,
wherein each document of the plurality of documents has a plurality of sentences, and each sentence of each document has m semantic embedding vectors, where m is an integer greater than 1;
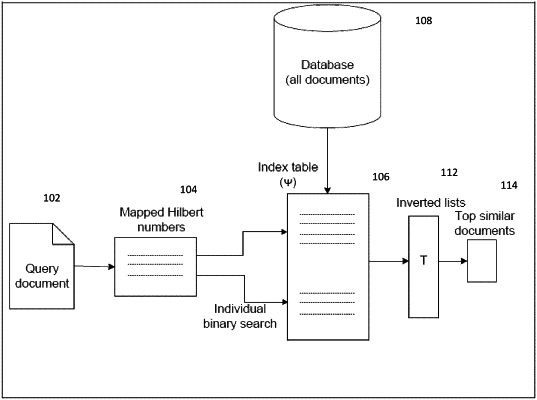
mapping, via a processing circuitry, the m semantic embedding vectors for each document of the plurality of documents to 1-dimensional vectors of Hilbert numbers using a Hilbert curve transformation;
constructing, via the processing circuitry, an index table with the plurality of 1-dimensional vectors; and
storing the index table in the memory,
wherein, in the mapping, the processing circuitry performs the Hilbert curve transformation by converting m embedding vectors into a Hilbert number and the Hilbert numbers are search keys in the index table,
the method further comprising:
performing a search using the initialized textual document search engine, by
receiving a query document, which has query embedding vectors;
searching, via the processing circuitry, the search keys in the index table; and
performing, via the processing circuitry, a filtration stage,
wherein the searching, via the processing circuitry, includes:
mapping the query embedding vectors into Hilbert numbers for the query document; and
performing a binary search based on the Hilbert numbers, and
wherein the performing the filtration stage, via the processing circuitry, includes:
outputting a predetermined number of candidate documents that are similar to the query document.
|