| CPC G10L 15/063 (2013.01) [G10L 15/02 (2013.01); G10L 15/10 (2013.01)] | 16 Claims |
|
1. A method for speech recognition, performed by a computing device, comprising:
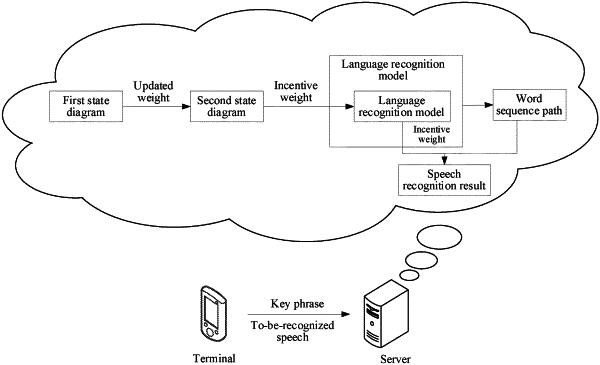
extracting a reference edge from a first state diagram, and searching a second state diagram for a target edge having a same label and a same prefix path as the reference edge, wherein: the first state diagram is a state diagram of a key phrase language model of a textual segment; the second state diagram is a state diagram of a basic language model; the first state diagram includes a plurality of nodes and at least one path for transitioning from one node to another node; and the first state diagram is used as a reference to modify the second state diagram;
adjusting, by using a weight of the reference edge that represents a relationship between at least one pair of elements in the first state diagram, a weight of the target edge;
mapping an incentive weight of an edge in a language recognition model corresponding to the target edge in the second state diagram to the adjusted weight of the target edge, the language recognition model being a language model obtained after the basic language model is pruned;
inputting a to-be-recognized speech into a speech recognition model comprising the language recognition model;
obtaining word sequence paths outputted by the speech recognition model for the to-be-recognized speech;
determining that a first edge in each word sequence path in the word sequence paths has a mapped incentive weight at an edge level;
determining that a second edge in the each of the word sequence paths in the word sequence paths does not have a mapped incentive weight at the edge level;
calculating a score of the each of the word sequence path based on the mapped incentive weight of the first edge and an initial weight of the second edge; and
selecting a target path from the word sequence paths which has a highest score based on the calculated score of each of the word sequence paths in the word sequence paths, to obtain the speech recognition result.
|