| CPC G06T 1/0028 (2013.01) [G06T 1/0064 (2013.01); G06T 1/0078 (2013.01); G06T 7/0002 (2013.01); G06T 11/00 (2013.01); G06T 2207/20016 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01)] | 7 Claims |
|
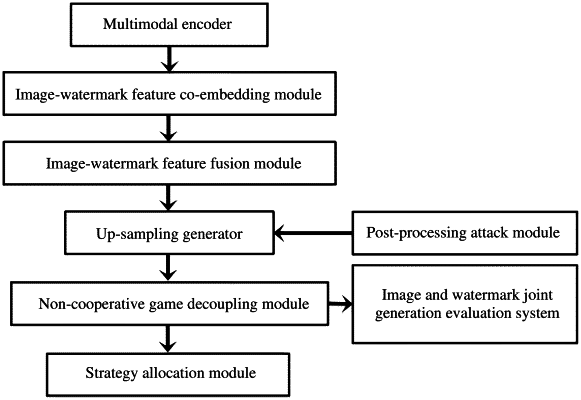
1. A cross-modal image-watermark joint generation and detection device, comprising:
an image-watermark feature co-embedding module, configured to map an original image feature and a watermark feature to a unified feature space by a learnable parameter matrix;
an image-watermark feature fusion module, configured to fuse the watermark feature and the original image feature at a channel level to acquire an image-watermark fusion feature and cascade the original image feature for a plurality of times;
an up-sampling generator, configured to map the image-watermark fusion feature into pixels to acquire a composite image with a preset resolution;
a non-cooperative game decoupling module, configured to allocate information of the composite image through two decoders by developing allocation strategies according to a non-cooperative game theory and a Shannon information theory to decouple an unwatermarked image and a reconstructed watermark;
a strategy allocation module, configured to set an image joint discriminator, extract features of the composite image by multi-specification down-sampling convolution kernels to constrain image-text semantic consistency and fidelity, and set an objective function to constrain reconstruction of watermark and unwatermarked image; and
a post-processing attack module, configured to simulate post-processing attacks and output a final image-watermark joint generated image;
wherein, the original image feature is obtained by a multimodal encoder, the multimodal encoder configured to extract features from an input text, noise sampling and a digital watermark by pre-trained natural language encoding models, multilayer perceptrons, and visual encoding models, and acquire feature representations thereof to obtain the original image feature through affine transformation using text features and noise features.
|