| CPC G06F 12/123 (2013.01) [G06F 12/0875 (2013.01); G06F 12/0891 (2013.01); G06T 1/60 (2013.01); G06F 2212/302 (2013.01)] | 24 Claims |
|
1. A graphics processing unit (GPU) comprising:
a plurality of groups of cores, each group of cores including:
a plurality of cores of a first type; and
a plurality of cores of a second type, wherein the plurality of cores of the second type are tensor cores;
a plurality of combined level 1 (L1) cache and shared memory units, each corresponding to a different group of cores of the plurality of groups of cores;
a level 2 (L2) cache to be shared by the plurality of groups of cores;
a plurality of memory controllers to couple the GPU to a memory; and
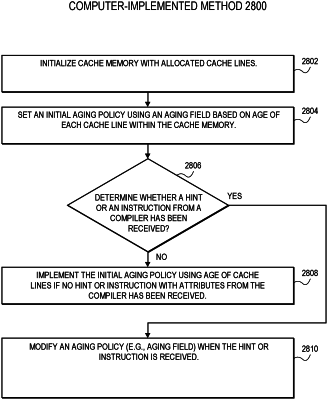
a cache controller associated with the L2 cache, in response to an instruction from a first core of the plurality of groups of cores, to:
apply a second cache eviction importance to a data in the L2 cache instead of a first cache eviction importance while the data in the L2 cache is to remain useable, wherein the second cache eviction importance is indicated by the instruction.
|